Missing values (ontbrekende gegevens) zijn gegevens of datapunten van een variabele die ontbreken. Het kan bijvoorbeeld veroorzaakt worden doordat een respondent vergeet een bepaalde vraag in een enquête in te vullen. Of een datum ontbreekt (in experimenteel onderzoek) door een mechanische fout. Een andere oorzaak is dat een respondent weigert een vraag te beantwoorden. Mogelijk omdat deze gevoelig ligt. Missing values kunnen een significant effect hebben op de conclusies die je kunt trekken op basis van de data. Dit betekent (in veel gevallen) niet dat we de data die we wel hebben in de vuilnisbank moeten gooien. Datatechnisch gezien kun je ook met missing values te maken krijgen wanneer je bijvoorbeeld in een enquête verschillende 'routes' toepast: verschillende typen respondenten (bv. klanten en prospects) krijgen verschillende vragen op basis van hun kenmerken of antwoorden. Wanneer je hier één dataset van maakt zullen er lege velden zijn, welke op de juiste wijze getypeerd dienen te worden, afhankelijk van de onderzoeksvraag die je wilt beantwoorden of hypothesedie je wilt toetsen.
Missing values coderen
Nu we weten wat missing values zijn en wanneer je hiermee te maken krijgt, een uitleg over hoe je hiermee om dient te gaan in SPSS. We dienen namelijk aan SPSS te vertellen wanneereen waarde of leeg veld als missing value wordt behandeld, maar vervolgens ook hoeeen missing value wordt behandeld. Dit gaat min of meer volgens hetzelfde principe als het coderen van variabelen: we kiezen een bepaalde numerieke waarde die het ontbrekende datapunt vertegenwoordigt. Deze waarde vertelt SPSS dat er sprake is van een missing value in een bepaald geval, bijvoorbeeld voor een specifieke respondent voor een bepaalde variabele. In de analyse negeert SPSS de datapunten die zijn aangemerkt als missing value. Uiteraard dien je ervoor te waken dat de numerieke waarde die je toekent aan missing values niet overeenkomt met een van de numerieke waarden die je in de codering van de variabelen hebt gebruikt. Stel dat je het getal 7 toekent aan missing values en hetzelfde getal komt ook in de antwoorden van je enquête. SPSS zal dan alle antwoorden die als 7 gecodeerd zijn als missing value behandelen.
Numerieke waarde toekennen aan missing value
Het toekennen van een numerieke waarde aan een missing value gaat als volgt:
Klik in de Variable View in de rij van de betreffende variabele in de cel onder de kolom Missing.
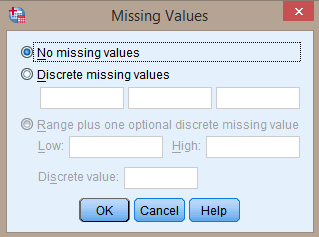
Vervolgens klik je op het blauwe hokje met drie puntjes dat verschijnt. Hiermee activeer je het venster Missing Values (zie afbeelding onder). De standaardinstelling is No missing values. Als dit inderdaad het geval is met jouw dataset dan hoef je hier niets aan te veranderen.
Er zijn twee manieren om missing values te definiëren. De eerste optie is Discrete missing values. Dit zijn enkelvoudige waarden die de ontbrekende data vertegenwoordigen. Je kunt maximaal drie verschillende discrete missing values invoeren. Je kunt voor meerdere waarden kiezen als je voor jezelf de betekenis van de missing value wilt differentiëren (bv. 6 = 'niet van toepassing', 7 = 'weet ik niet' en 99 = 'geen antwoord ingevuld'). De tweede optie is Range plus one optional discrete misssing value. Deze optie is handig wanneer je data tussen die tussen twee punten valt buiten de analyse wilt houden. Tenslotte kun je bij deze laatste optie nog kiezen voor een aanvullende discrete missing value.
Listwise of pairwise deletion?
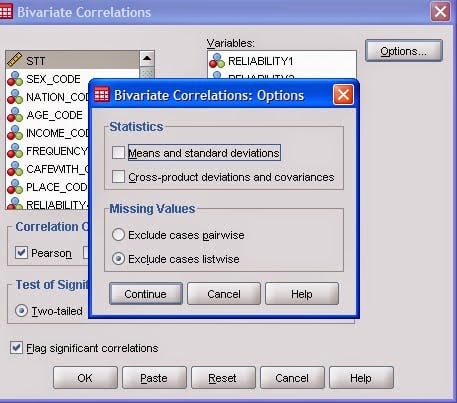
Wanneer je de missing values hebt gecodeerd en je aan je analyse begint duikt er een nieuw vraagstuk op met betrekking tot missing values: listwise of pairwise deletion? Listwise betekent dat elke case (bijv. een respondent) met een missing value buiten de analyse wordt gehouden. Pairwise houdt in dat SPSS alleen de missing values laat vallen en de rest van de case behoudt. Bijvoorbeeld, van een respondent die haar leeftijd niet heeft ingevuld, neem je wel ingevulde velden mee. Beide methoden hebben doen dus totaal verschillende aannamen over de manier waarop met data wordt omgegaan. Je zult doen even moeten nadenken, met het doel van jouw onderzoek in je achterhoofd, wat de meest passende vorm is om met missing values om te gaan. In SPSS kun je jouw keuze aangeven in het optiescherm bij de betreffende analyse die je gaat uitvoeren (hier onder een voorbeeld).
Door
Yoni
op
12 Jul 2020
Beste Luuk,
Ik voer onderzoek naar werkdruk en burn-out in het onderwijs. Voor mijn statische analyse zou ik mijn Likertschaal Nooit Zelden Soms Vaak Altijd
(score van 1 tot 4 dus) willen omzetten naar score van 0 tot 10 in SPSS, hoe krijg ik dat voor me mekaar.Ik had het volgende reeds bedacht [ (omzetten 1-4 naar 0-10 met formule: (a=1, b=4, A=0, B=10): Y = (B-A)*(x-a)/(b-a)+A
concreet: bijv je hebt 2 op 4; wordt een score op 10 van: Y = 10*(2-1)/(4-1)+0= 3,33
In SPSS dus de formule in (DE te berekenen variabele bijv werkdruk gemiddeld op 10) = (10*werkdruk gemiddeld op 4 - 1)/3, en zo voor de 9 andere schalen] maar kan je me concreet in SPSS 25 aanduiden / of een bron bieden waar/hoe deze stappen, al dan niet visueel, worden gedaan, ben vrijwel een leek hierin. Het is een beetje dringend. Alvast bedankt voor je hulp.
Groeten, Yoni
Reageren
Door
Luuk Tubbing
op
12 Jul 2020
Beste Yoni,
Het omzetten van een variabele doe je met de functionaliteit 'Compute Variable'. Als je dit googeled vind je talloze tutorials.
Overigens weet ik niet of ik jouw uitleg goed begrijp. Ik tel een 5-puntsschaal (Nooit, Zelden, Soms, Vaak, Altijd), niet 1-4... Als je dit omzet naar 1-10 (0 zou ik gebruiken voor non-respons/missing values/nvt) is het een kwestie van de score met 2 vermenigvuldigen . Waarom wil je trouwens de scores omzetten? Dit kan namelijk voor de lezer van jouw scriptie een verkeerd beeld geven. Op een 10-puntsschaal krijg je vanzelfsprekend meer verfijnde scores dan op een 5-puntsschaal. Als je van 5 naar 10 omzet mis je de tussenliggende (oneven) scores.
Groeten,
Luuk
Reageren
Door
Yanne
op
10 Apr 2020
Beste Luuk,Ik voer onderzoek naar de impact van het geslacht van de bedrijfsleiding op de vraag naar formeel risicokapitaal. Hierbij zijn enkele determinanten gekend (zoals ondernemingsgrootte, ...) die de vraag naar formeel risicokapitaal beïnvloeden en hierbij verschillen tussen mannen en vrouwen. Ik voer hierbij meervoudige logistische regressies uit. Enerzijds met als afhankelijke variabele 'geslacht' en anderzijds met als afhankelijke variabele 'de voorkeur voor het gebruiken van formeel risicokapitaal'. Beide variabelen zijn dus binair gecodeerd. Mijn model bestaat uit ongeveer 15 onafhankelijke variabelen. Nu heb ik het probleem dat bij twee van deze variabelen slechts 25 van de 81 respondenten een antwoord aangeduid hebben. Ik ken hierbij dus 56 missing values. De variabelen zijn beide schaalvariabelen. Nu vroeg ik mij af hoe ik hier in deze specifieke case mee kan omgaan. Als ik de LOGIT regressie met inbegrip van de twee variabelen met weinig respons wil uitvoeren krijg ik de melding: 'perfect prediction obtained: no MLE exists' op het programma Gretl. Bij SPSS bekom ik bij block : method = enter ook geen tabel met de uitkomsten van de logistische regressie. Wanneer ik de twee variabelen weglaat bekom ik wel een model. Ik vraag mij af hoe ik deze twee variabelen toch kan betrekken bij het onderzoek.
Reageren
Door
Mariska
op
17 Mar 2020
Hi Luuk,
Ik ben mijn data aan het coderen en loop nu tegen een hele lage chronbach alfa aan bij de ja/nee/n.v.t. vragen. Ik denk dat ik ze niet goed heb gecodeerd
Ik heb twee soorten vragen in mijn vragenlijst zitten 1 de vijfpunt likerschaal en de ja/nee/n.v.t vragen.
Ik heb de ja/nee/nvt gecodeerd als ja=3, nee=2, en nvt=1.
En kom nu op een crohnbachalfa van 0.428. De andere vragen waar geen ja/nee/nvt in zit komen allemaal wel op een 0.8/0.9.
Reageren
Door
Luuk Tubbing
op
17 Mar 2020
Hi Mariska,
Waarschijnlijk heeft dat niets te maken met het coderen. Wellicht krijg je een lage Cronbach's Alpha omdat de vraagstelling inconsistent is (bijv. omdat een deel van de vragen negatief/ontkennend geformuleerd is, zonder dat je hier rekening mee houdt in de codering) of omdat de vragen simpelweg niet hetzelfde meten (dat is wat je toetst).
Reageren
Door
Feray
op
22 Jan 2020
Hoi,Bedankt voor de heldere uitleg! Dit heb ik allemaal toegepast, maar de Chi2 toets pakt het niet. Dit is aan de hand:1. Ik heb een dataset met jongeren en een dataset met ouders samengevoegd tot één dataset (add cases).
2. Beide datasets (dus zowel jongeren als ouders) hebben antwoord gegeven op eenzelfde vraag (eenzelfde variabele)
3. Deze variabele bevat nu in de samengestelde dataset de antwoorden van zowel jongeren als ouders.
4. Ik wil graag een Chi2 toets uitvoeren (de variabele heeft 3 categorien) om te kijken of de antwoorden significant van elkaar verschillen tussen jongeren en ouders, en of dat misschien enkel door toeval komt.
5. Nu maak ik vanuit deze gecombineerde (jongeren + ouders) variabele, twee nieuwe variabelen. Een variabele bevat enkel de antwoorden van jongeren, en dus GEEN antwoorden van ouders. En een variabele met enkel de antwoorden van ouders, en dus GEEN antwoorden van jongeren.
6. Wanneer ik de missing values als '99' aangeef in variable view, en vervolgens de Chi2 toets aanzet, krijg ik de melding "The crosstabulation of tiener * parents is empty". Dit kreeg ik overigens ook voordat ik de missing values erin plaatste.
7. Wanneer ik een dubbel check met descriptives doe, zie ik zowel bij ouders als bij jongeren de correcte aantal respondenten. Het ligt dus echt aan het feit dat bij allebei de nieuwe variabelen een hoop vakjes leeg zijn.P.S. Ik weet niet zo goed of we die lege vakjes missing values kunnen noemen, omdat de antwoorden van de andere groep populatie wel bestaat in de dataset (alleen zijn die geexcludeerd uit die ene nieuwe variabele).Zie jij wat hier misgaat en wat ikzelf over het hoofd zie? Hoe kan ik toch een Chi2 uitvoeren (eventueel binnen de originele variabele)??
Zou het enórm waarderen als je mij hierbij zou kunnen helpen!Groetjes, Feray
Reageren
Door
Luuk Tubbing
op
22 Jan 2020
Hoi Feray,
Punt 5 volg ik niet. Waarom heb je die twee nieuwe variabelen gemaakt? Is dat om de jongeren en ouders te kunnen herkennen in de data? Normaliter zou ik dat doen door een kolom toe te voegen waar je aangeeft om welke groep het gaat (bijv. 'leeftijdsgroep' als variabele, met 'tiener' en 'oudere' als waarden). Of praten we langs elkaar heen?
Groetjes,
Luuk
Reageren
Door
Ymkje
op
29 Jul 2019
Beste Luuk,
Is het mogelijk om een bepaald aantal van mijn system missings een andere waarde toe te kennen dan de rest?
De context: ik probeer de gewerkte uren van twee groepen over tijd met elkaar te vergelijken. Ik heb dus twee groepen, maar nu heb ik in groep 2 meer missings values dan in groep 1. De missing values moeten worden gecodeerd als een '0', gezien deze mensen nul uren werken. Maar doordat het aantal missings in groep 2 groter is dan in groep 1, trekt dit het gemiddelde naar beneden. Nu dacht ik, wat nou als ik een gedeelte van de missings van groep 2 aanvul met het gemiddelde gewerkte uren van groep 2 totdat het er evenveel zijn als in groep 1, dan wordt het gemiddelde veel minder naar beneden getrokken. Is dit mogelijk? En zo ja, hoe?
Reageren
Door
Luuk Tubbing
op
30 Jul 2019
Beste Ymkje, ik snap niet precies wat het probleem is en waarom je dit op deze wijze wilt oplossen. De 0 moet je niet zien als 0 uren gewerkt, maar als een missing value. Normaal gesproken laat je de missing values uit de berekening van het gemiddelde. Kom je hier verder mee?
Groeten,
Luuk
Reageren
Door
Emma
op
21 May 2019
Hoi Luuk,
Voor mijn afstudeer onderzoek heb ik door 5 artsen 50 patiënten laten beoordelen op 3 categorieën.
1. waar kwamen de patiënten mee langs (hierbij moesten triggers worden gedefinieerd uit een lijst. Indien het event niet op de trigger lijst stond kon er 'niet van toepassing' worden ingevuld.
2. aan de hand van de medicatie die ze gebruikten heb ik laten beoordelen of het event door de medicatie veroorzaakt zou kunnen zijn (causaliteit; let op, hierbij heb ik ze ook de keuze niet van toepassing gegeven, als er geen medicatie in gebruik was die voor het 'event/trigger' zou kunnen zorgen.
3. Als het even/trigger door medicatie veroorzaakt was, moesten ze ook de mogelijke kans op vermijdbaarheid invullen (zeker, misschien, niet vermijdbaar). Ook hier kan dus niet van toepassing worden ingevuld (indien geen trigger uit de lijst, of niet causaal).
Nu wil ik de 'nvt' omzetten in een 0 waarde, aangezien het geen missing value is, maar ook een antwoord. Hier wil ik later een Fleiss Kappa over berekenen om te zien hoe eens alle artsen het met elkaar zijn.
Hoe vul ik een missing value in? (dat het een 'waarde)' krijgt?Groet,Emma
Reageren
Door
Luuk Tubbing
op
21 May 2019
Beste Emma,
Ik begrijp je vraag niet precies. Wellicht is deze te complex voor deze plaats. Ik doe toch een poging. Nvt omzetten in een 0-waarde zou ik zelf met Excel doen (met zoeken en vervangen) en dan de dataset opnieuw in SPSS inladen. Als je Googled op 'SPSS convert string to numeric' vind je het antwoord denk ik wel.
In bovenstaande artikel staat uitgelegd hoe je een missing value invult.
Is dit een antwoord? Succes!
Groet,
Luuk
Reageren
Door
Katrien
op
15 May 2019
Hoi Luuk,Mijn databestand bestaat uit 79 cases (proefpersonen), 2 relevante afhankelijke variabelen (uitkomsten op taak A en taak B), 1 onafhankelijke between-subjectfactor (conditie 1 en conditie 2) en 1 onafhankelijke within-subjectfactor (voormeting en nameting).Ik ga hierop twee 2x2 repeated measures ANOVA's uitvoeren (1 voor iedere afhankelijke variabele).Voor variabele A (taak A) heb ik missing values bij 4 cases
Voor variabele B (taak B) heb ik missing values bij 6 cases
De missing values bij taak A en B zijn echter bij compleet andere proefpersonen.Vraag 1:
Ik dacht dat pairwise deletion dan het beste zou zijn, omdat ik anders 10 cases moet excluderen van analyse. Klopt dat?
Bij listwise deletion zou ik gelijk nog maar 69 cases hebben.. Ik weet niet precies of mijn power dan te laag wordt..Vraag 2:
In het geval dat pairwise deletion inderdaad het beste is - hoe rapporteer ik dan de 'participants characteristics' in de methodesectie? rapporteer ik deze dan toch over het totaal aantal (79 participanten) - of apart voor de 75 cases voor afhankelijke variabele A (taak A) en de 73 cases voor afhankelijke variabele B (taak B).Met vriendelijke groet,Katrien
Reageren
Door
Luuk Tubbing
op
17 May 2019
Hoi Katrien,
Pairwise lijkt mij inderdaad de meest passende keuze. In de methodesectie rapporteer je de karakteristieken over het totaal en eventueel ook nog over subgroepen (als die doelbewust verschillend zijn qua karakteristieken - een taak lijkt mij geen karakteristiek). Helder? Succes!
Met vriendelijke groet,
Luuk
Reageren
Door
Bettine
op
18 Apr 2019
Dag Luuk,
Ik ben bezig met de missing values en verschilllende data die ik niet in mijn analyse wil hebben te filteren. Ik heb een variabele aangemaakt die ik 'accepted' heb genoemd waarbij data een '1' krijgt die wel mee mag doen en data een '2' krijgt die niet hoeft mee te doen. Ik heb laatst iets gedaan waardoor er streepjes in de eerste rij van de data kwam te staan die ik een 2 had gegeven. Echter, ik heb SPSS toen afgesloten en is dit toen ook weggegaan. Het probleem is dat ik nu niet meer weet hoe ik dit heb gedaan. Ik heb heel internet afgezocht maar kom steeds uit op missing values niet meenemen, maar dit is iets anders dan wat ik bedoel. Ik hoop dat u mijn vraag begrijpt en mij kan helpen!
Ik hoor graag van u.Groet,
Bettine
Reageren
Door
Floor
op
01 May 2019
Ik zit nu met hetzelfde probleem en krijg de streepjes niet meer weg. Wat ging er precies mis en hoe is het opgelost?
Reageren
Door
Bettine
op
18 Apr 2019
Ik heb het al gevonden!
Reageren
Door
Nadianne van den Ende
op
19 Mar 2019
Beste Luuk,
Ik heb geprobeerd het antwoord te vinden in eerdere reacties, maar ben het volgens mij nog niet tegengekomen. Ik heb voor 1 enquête 2 strata, ik doe namelijk onderzoek naar leerlingen die een maatschappelijk programma volgen op school. 1 strata volgt alleen de workshops en de andere strata volgt zowel de workshops als de maatschappelijke voetbalcompetitie. De eerste 20 vragen van mijn enquête gaan over de workshops en kunnen beide strata beantwoorden. Daarna volgen er vragen die over de voetbal gaan en is strata 1 klaar met de enquête. Hoe verwerk ik dit juist in SPSS? Ik ga de 2 strata namelijk ook vergelijken om te kijken of zij de workshops wellicht anders beoordelen. Moet ik dan als ik strata 1 invul de vragen over de voetbal als missing value ''niet van toepassing'' coderen?
Reageren
Door
Luuk Tubbing
op
20 Mar 2019
Beste Nadianne, deze vraag wordt regelmatig gesteld. Voor de vragen over voetbal analyseer je dan alleen de groep die het heeft ingevuld. Je kunt met een variabele aangeven welke groep het was of hier aparte dataset maken met alleen de voetbalresultaten. Helder?
Groeten,
Luuk
Reageren
Door
Lieke
op
14 Feb 2019
Beste Luuk,
In mijn onderzoek heb ik meerdere databases samengevoegd. Als gevolg hiervan zijn er voor één patiënt meerdere regels aangemaakt. Het samenvoegen van de databases heeft echter tot gevolg dat bijv. geboortedatum en operatiezijde vaak slechts alleen in de eerste regel over de patiënt zijn ingevuld (omdat dit slechts in één van de samengevoegde bestanden beschreven staat). Hierdoor zijn er veel missende waarden in de samengevoegde database, wat in de praktijk geen missende waarden zijn. Graag zou ik deze velden (voor het draaien van de database van lang naar breed) alsnog vullen. Kunt u mij vertellen hoe ik dit aan kan pakken? Is hier een specifieke syntax voor?
Alvast bedankt.
Met vriendelijke groet,
Lieke
Reageren
Door
Michel
op
27 Mar 2020
Hartstikke bedankt voor je snelle reactie, Luuk! Ik had dat niet zo snel verwacht.
Merge files zorgt er helaas voor dat alleen de bovenste case wordt gekoppeld aan de nieuwe variabele, zoals Lieke ook bij haar onderzoek omschrijft. Ik heb SQL gedownload maar oef dat is een syntax al syntax en die taal spreek ik nog niet helemaal. Ik heb de gegevens niet in mooie Excel tabellen, dus als ik met SPSS toch die datatransformatie kan doen zou fijn zijn. Het kan evt ook handmatig kopiëren en plakken maar dat is minder aangezien het 13000 cases zijn en sws minder goed te verantwoorden. Ik hoor het graag als ik het automatisch kan oplossen met SPSS!
Reageren
Door
Michel
op
25 Mar 2020
Hi,
Ik heb hetzelfde probleem! Heb jij een oplossing?! Handmatig is het niet te doen en ook niet goed te verantwoorden. SQL ben ik niet bekend mee en Excel doet ook niet wat ik wil. Dus bij deze een oproep hoe ik het kan oplossen.
Reageren
Door
Luuk Tubbing
op
25 Mar 2020
Hi Michel,
Als je 'merge files in spss' googelt vind je het antwoord. Er zijn allerlei manieren om twee bestanden in SPSS samen te voegen.
Reageren
Door
Luuk Tubbing
op
14 Feb 2019
Beste Lieke,
Daar kan ik je helaas niet mee helpen wat betreft SPSS. Zelf gebruik ik voor dergelijke datatransformaties MS Excel (mbv de 'vlookup' functie) of SQL ('joinen' van verschillende tabellen), aangezien SPSS daar niet goed in is.
Met vriendelijke groet,
Luuk
Reageren
Door
Jildou
op
29 Jan 2019
Hoi Luuk,
Ik ben bezig met mijn masterscriptie en wil graag het gemiddelde van twee groepen weergeven. Nu heb ik variabelen die uit meerdere items bestaan en op sommige items hebben repsondenten geen antwoord gegeven, maar ik wil wel graag dat het gemiddelde van de variabele (op de ingevulde items) wordt weergegeven. Hoe kan ik dit instellen? Want pairwise deletion neemt de variabelen waarvan 1 item niet is ingevuld niet mee in het gemiddelde....mvg
Reageren
Door
Luuk Tubbing
op
29 Jan 2019
Hoi Jildou, pairwise deletion betekent dat SPSS alleen de missing values laat vallen en de rest van de case behoudt. Het gemiddelde wordt dan dus berekend over de overgebleven waarden.
Reageren
Door
Jantien
op
02 Jan 2019
Hi! Bij de enquête voor mijn master thesis kregen respondenten één van de zes condities voor zich (in wezen dezelfde vragenlijst maar dan met verschillend stimulus material). Deze categorieën wil ik met elkaar vergelijken om te kijken welke van de stimulus material de meeste invloed heeft op de onafhankelijke variabelen.
Nu is het alleen zo dat elke respondent veel system missing values heeft, omdat 5 condities niet ingevuld zijn. Ook zijn er verschillende routes binnen de enquête (waardoor sommige vragen wel/niet beantwoord worden). Hoe kan ik dit het beste/makkelijk weergeven in de dataset, gezien alle responses door elkaar staan en niet gefilterd zijn? Met of zonder missing values? Ook in verband met de factor analyse en Cronbach's alfa.
Alvast bedankt!
Reageren
Door
Luuk Tubbing
op
13 Jan 2019
Hi Jantien, ik snap je vraag niet goed. Kun je deze specifieker maken? Wat bedoel je met weergeven in de dataset? Het gaat er uiteindelijk om dat je per analyse de juiste groep respondenten includeert. Uiteraard alleen degenen die de vragen hebben beantwoord, ervan uitgaande dat het niet mogelijk was om vragen over te slaan (los van vooraf bepaalde routes).
Groeten,
Luuk
Reageren
Door
Britt
op
17 Nov 2018
Hoi!
Ik onderzoek het effect van geslacht en ervaring op financiële beslissingen met een regressie-analyse in een steekproef van 165 mensen. Ik heb een paar missing values. Moet ik de regressie-analyse doen met "listwise deletion" of "pairwise deletion"?
Reageren
Door
Luuk Tubbing
op
17 Nov 2018
Hoi Britt,
Dat kan ik o.b.v. deze informatie niet bepalen, want hangt af van de aard/reden van deze missing values. Je kunt pairwise toepassen als de respondenten met missing values representatief zijn voor de populatie.
Reageren
Door
Katrin
op
28 Jul 2018
Dag Luuk,
Bedankt voor de uitleg allereerst. Ik heb inderdaad -2 als discrete missing value aangeduid in mijn data.
Ik ben momenteel mijn missing values aan het proberen aanvullen in SPSS (volgens een youtube tutorial). Ik analyseer dus mijn missing values, alles correct. Transform, random number generators,... Dan doe ik multiple imputation, impute missing values en geef alles aan. En dan scan ik m'n data om zo de constraints aan te duiden, maar na het scannen geeft hij dan aan dat mijn min value = 1 en heeft hij 0 meegerekend als onbekende waarde, terwijl dat nergens zo staat aangeduid. Ik loop echt muurvast hierop helaas.
Reageren
Door
Luuk Tubbing
op
29 Jul 2018
Dag Katrin,
Bedankt voor je vraag. Op basis van deze uitleg kan ik niet aangeven waar precies het probleem en de oplossing zit. Als je behoefte hebt aan persoonlijke hulp hierbij kun je je hier aanmelden: https://deafstudeerconsultant.nl/scriptiehulp/ Dan wordt je door een van onze begeleiders verder geholpen.
Groeten,
Luuk
Reageren
Door
Jildou
op
22 Jul 2018
Hoi Luuk,
Dit stappenplan heb ik al gevolgd. Als ik nu een nieuwe variabele maak door de verschillende items bij elkaar op te tellen (zoals in mijn eerste vraag beschreven), dan houdt SPSS er automatisch rekening mee dat dit wordt gedeeld door het aantal opgetelde waarden te delen door het aantal antwoorden (waarbij je de missing values buiten beschouwing laat)? Of moet ik dat zelf instellen door 'if 99...' oid?Met vriendelijke groet,
Jildou
Reageren
Door
Luuk Tubbing
op
22 Jul 2018
Hoi Jildou, ik weet niet of SPSS automatisch rekening houdt met missing variables bij gebruik van de compute functie van SPSS. Mijn antwoorden gaan over het berekenen van gemiddelden in het algemeen (los van SPSS) en omgaan met missing values (los van de compute functie). Hoe beide functies samenwerken durf ik niet te zeggen.
Reageren
Door
Jildou
op
21 Jul 2018
Hoi,
Ik maak gebruik van een enquête voor mijn onderzoek. Verschillende vragen meten 1 variabele. Nu wou ik voor het meten van het gemiddelde en standaarddeviatie van de variabele de data van de verschillende vragen bij elkaar optellen. Maar doordat ik missing heb, geeft dit een vertekend resultaat van het gemiddelde (deze wordt niet meegenomen namelijk, maar kan net zo goed een laag gemiddelde veroorzaken). Hoe kan ik dit voorkomen?Bijvoorbeeld voor het meten van contact worden 5 vragen met als antwoordcategorie van 1 t/m 5 lopend van 1 = weinig contact en 5 = veel contact bij elkaar opgeteld. De missing zorgen ervoor dat hetl lijkt alsof er weinig contact is, maar de missing geeft juist aan dat een respondent het niet weet. Hoe kan ik dit het best oplossen?
Reageren
Door
Luuk Tubbing
op
22 Jul 2018
Hi Jildou, in bovenstaande artikel staat uitgelegd hoe je missing values buiten je berekening kunt houden. Beter dan dat kan ik het niet uitleggen.
Reageren
Door
Jildou
op
21 Jul 2018
Dag Luuk,Wat fijn dat je zo snel reageert. Dat is een goede manier lijkt mij. Zo geven de missing values geen vertekent beeld van het eigenlijke gemiddelde. Is er ook een manier hoe ik dit het best kan verwerken in SPSS? Want hier kom ik helaas niet helemaal uit.Met vriendelijke groet,
Jildou
Reageren
Door
Luuk Tubbing
op
21 Jul 2018
Hoi Jildou,
Dit kun je oplossen door de opgetelde waarden te delen door het aantal antwoorden (waarbij je de missing values buiten beschouwing laat). Het gaat er dus niet zozeer om hoe je de berekening uitvoert, maar welke waarden je wel of niet includeert. Helder?
Extra tip: rapporteer naast het gemiddelde ook de mediaan (de middelste waarde in de verdeling). Deze geeft een goed beeld van het 'typisch' antwoord, terwijl een gemiddelde vertekend kan zijn door een scheve verdeling en outliers (hoewel jij geen extreme outliers zult hebben, omdat je een ordinale schaal gebruikt).
Succes!
Groeten,
Luuk
Reageren
Door
HenkJan
op
11 Jul 2018
Zou je ipv dit hierboven de missing values ook gewoon als nul kunnen invoeren? Voordat je in SPSS inleest
Reageren
Door
Luuk Tubbing
op
11 Jul 2018
Ook als je van te voren de missing values een 0-waarde geeft zul je deze in SPSS moeten definiëren, zodat SPSS weet welke waarden als missing gezien moeten worden en deze op de juiste manier meeneemt in berekeningen.
Reageren
Door
Smithd0
op
15 Jun 2018
This website is mostly a walkby for all the info you wished about this and didnt know who to ask. Glimpse right here, and also youll undoubtedly uncover it. ggcdkkdgeaefcfec
Reageren
Door
John
op
23 May 2018
Beste, Bedankt voor jullie leerzame uitleg steeds op de website. Ik heb een vraag m.b.t. hercoderen van een 'tegenstellings' vraag in mijn enquete. De vraag is als volgt:Ik denk dat deze technologie..
Veel slechter voor X zal zijn 1 2 3 4 5 Veel beter voor X zal zijn
Zeer weinig zal bijdragen aan Y 1 2 3 4 5 Zeer veel zal bijdragen aan Y
Ik neem aan dat ik de 1-5 gewoon codeer net als een normale vraag(1 = veel slechter, 2=slechter, 3=neutraal, veel=beter, 5=veel beter, etc.) ? Of bestaat er voor tegenstellings vragen een speciale manier?Mvg,
John
Reageren
Door
Luuk Tubbing
op
25 May 2018
Beste John, fijn dat je de uitleg op onze website leerzaam vind.
Zover ik weet is er niet zoiets als een 'tegenstellingsvraag' die om aparte behandeling vraagt. Het gaat er uiteindelijk om dat een vraag valide (meten wat je beoogd te meten) en betrouwbare (nauwkeurig en precies) antwoorden oplevert. Belangrijk is dat de meetschalen voor de respondent begrijpelijk en consistent zijn. Dus zoveel mogelijk dezelfde schalen toepassen, gelijke intervallen en labeling van antwoorden gebruiken, etc.
Reageren
Door
Sara
op
12 May 2018
Beste Luuk,
Ik wil graag een gemiddelde score van mijn vragenlijst omzetten in procenten. Nu heeft mijn likert schaal:
1 = >90%
2 = 75%
3 = 50%
4 = 25%
5 = 10%
al percentage gekoppeld aan cijfers. Alleen zijn mijn gemiddeldes andere waardes zoals 2,69. Hoe kan ik de 2,69 omzetten in percentages aan de hand van deze likertschaal?Met vriendelijke groet,
Sara
Reageren
Door
Luuk Tubbing
op
13 May 2018
Beste Sara,
Waar wil je deze percentages voor gebruiken? Het is namelijk ongebruikelijk en misleidend om resultaten van een Likertschaal als percentages te rapporteren. Wil je dit toch doen, dan zou ik de hoogste waarde labelen als 100% (nu >90%) en de laagste als 0% (nu 10%). Dan heb je telkens een interval van 25%. Het omzetten doe je door de waarden te hercoderen: Transform > Recode into Different Variables.
Met vriendelijke groet,
Luuk
Reageren
Door
Ella
op
16 Apr 2018
Beste Luuk,Bedankt voor de uitleg! Ik ben bezig met mijn scriptie, maar weet niet hoe ik precies met de missings om moet gaan. Ik doe een longitudinaal onderzoek, waarbij ik de cases wil wissen die op het derde meetmoment een bepaalde vraag niet hebben beantwoord. Deze cases staan in de variable view geregisteerd als -999, system missing. Als ik vervolgens bij de data view kijk, staat er inderdaad soms -999, maar ook heel vaak gewoon een leeg hokje (-). Wat is dan het verschil hier tussen? En hoe zorg ik ervoor dat ik de cases die op het derde meetmoment niet hebben geantwoord uit de dataset haal?Ik hoop dat ik mijn probleem zo duidelijk heb uitgelegd, alvast bedankt voor je reactie!
Reageren
Door
Luuk Tubbing
op
16 Apr 2018
Beste Ella,
Wat het verschil is in betekenis tussen een leeg hokje en -999 hangt af van wat degene die het heeft gecodeerd hiermee bedoelt. Zorg er eerst voor dat je alle missing values eenduidig codeert. Vervolgens kun je deze listwise of pairwise verwijderen uit de dataset. Deze stappen staan in het artikel hierboven beschreven.
Groeten,
Luuk
Reageren
Door
Sara
op
13 Apr 2018
Beste Luuk,Ik ben momenteel ook bezig mijn masterscriptie en ik kom niet echt uit.
Ik heb een vragenlijst met een 6punts likert schaal, waarbij de 6 staat voor weet ik niet.Ik wil deze vragenlijst beschrijven met beschrijvende statistiek (gemiddelde etc.) Alleen kwam ik er achter dat ik de 6 niet als hoge waarde kan hebben, omdat mijn resultaten dan niet zullen kloppen. Nu ben ik erop gekomen om de Likertschaal te hercoderen.Nu vroeg ik me af of ik van de 6 een 0 mag maken als waarde? Dus dat ik dit doe:
6 = 0
5 = 1
4 = 2
3 = 3
2 = 4
1= 5Ik heb vanuit school uit altijd geleerd dat de 6 = 1 wordt en de 1 = 6, maar als ik dit doe, dan kloppen mijn resultaten alsnog niet, want dan zal de score 1 het gemiddelde verpesten.Ik hoop dat je mijn vraag een beetje begrijpt
Reageren
Door
Luuk Tubbing
op
16 Apr 2018
Beste Sara,
Deze hercodering is prima. Echter kan de nul ook het gemiddelde verstoren. Het gaat erom dat je deze waarde buiten de analyse laat van (in ieder geval) de centrummaten.
Reageren
Door
Tessa
op
17 Mar 2018
Hee Luuk,
Ik heb een vraag, ik heb 15 vragen samengevoegd tot een nieuwe variabele, nu wil ik enkel de respondenten meenemen die op deze variabele niet meer dan 5 missende waardes hebben, weet jij toevallig hoe ik dit in SPSS moet doen. Met google kan ik het niet vinden... Zou heel fijn zijn als je dit toevallig weet!
Groet, Tessa
Reageren
Door
Luuk Tubbing
op
17 Mar 2018
Hee Tessa,
Ik zou niet weten hoe je dit op een nette manier kunt doen. Je kunt natuurlijk handmatig uitzoeken welke respondenten je niet wilt meenemen en bij hen de toegevoegde variabele verwijderen.
Succes!
Groet,
Luuk
Reageren
Door
Rob
op
16 Jun 2017
Hoi Luuk, ik heb een vraag over missing values i.c.m. een binary logistic regression. Is het mogelijk om aan missing values een waarde te hangen (die verder niet in de dataset voorkomt) zonder deze in de Variable View aan te geven als missing value? Of beinvloedt dit de resultaten van de andere values? Wanneer ik de missing value namelijk wel aangeef, krijg ik een foutmelding in de output. Alvast bedankt! Groeten, Rob
Reageren
Door
Luuk Tubbing
op
16 Jun 2017
Hoi Rob,
Het is zeker mogelijk om aan missing values een waarde te hangen (zie uitleg in bovenstaande artikel). Dit zal de resultaten van de andere values niet mogen beinvloeden. Ik kan zo niet beoordelen waarom (en welke) foutmelding je krijgt.
Succes Rob!
Groeten, Luuk
Reageren
Door
Judith
op
23 May 2017
Hallo,
Als je missende waardes hebt op je afhankelijke variabele, kan je de deelnemers dan net zo goed verwijderen of niet? Ik hoor het graag, alvast bedankt voor de hulp.
Groeten,
Judith
Reageren
Door
Luuk Tubbing
op
24 May 2017
Hallo Judith, klopt. Deze deelnemers als non-response meetellen.
Groeten,
Luuk
Reageren
Door
Eva
op
19 May 2017
Hallo, ik heb een vraagje hoe je missende waardes uit je analyses kan halen. Ik doe een onderzoek naar agressie bij kinderen. De training bestond uit 5 sessies. Ik wil graag alleen kinderen meenemen in de analyse die minstens 5 sessies hebben bijgewoond. Nu komt uit elke sessie ook weer data van een voormeting, trainingsmeting en nameting. Hoe kan ik dit in SPSS het beste de betreffende personen verwijderen (of als missing erin zetten)?
Reageren
Door
Luuk Tubbing
op
20 May 2017
Hallo Eva, daar zijn allerlei manieren voor. Je kunt bijvoorbeeld missing values van de cases die je wel wilt meenemen met een ander getal coderen dan de missing values van de cases die je niet wilt meenemen. Daar kun je dan je selectie op maken met de bovenstaande artikel beschreven methode. Helder Eva? Succes!
Reageren
Door
Eva
op
07 May 2017
Hallo Luuk, ik heb een vraag over het verwerken van missings in een tabel, want ik neem aan dat je deze niet zomaar achterwege kan laten. Ik heb 94 dossiers onderzocht en bij een bepaalde vraag zijn er twee missings en voor de andere 92 dossiers geldt allemaal het zelfde antwoord namelijk JA. Bij Valid Percent staat 100%. Ik heb geleerd dat je altijd naar Valid Percent moet kijken. Maar dat zijn niet de 94 dossiers maar 92. Zet je dan bovenaan de tabel (n=94) en in de tabel JA - 100% (92)
en verklaar je dan het verschil van 2 in de begeleidende tekst? Ik hoop dat mijn vraag zo duidelijk is. Alvast heel erg bedankt.Vriendelijke groeten,Eva
Reageren
Door
Luuk Tubbing
op
08 May 2017
Hallo Eva,
Bedankt voor je vraag. Ik begrijp de vraag echter niet helemaal en in vermoed dat ik voor het antwoord meer informatie nodig heb, zoals wat het doel is van de tabel waar je het over hebt en wat het belang is van de variabele waar de missing values zitten.
Vriendelijke groeten,
Luuk
Reageren
Door
Eva
op
19 May 2017
Ik heb bijvoorbeeld 5 sessies en daarin moesten de kinderen een test doen. Een aantal kinderen hebben niet alle sessies bijgewoond en deze wil er er graag uit hebben. Ik wil alleen de kinderen meenemen die minstens vier sessies hebben bijgewoond.
Reageren
Door
Roos
op
03 May 2017
Hoi Luuk,Fijn en duidelijk artikel. Hoe ik de missende waarde kan opgeven via het menu begrijp ik nu. Maar is het ook mogelijk om dit via de syntax te doen? De syntax die ik gebruik moet vaak door verschillende mensen worden gebruikt. En elke keer het enorme databestand meesturen is geen optie. Ik hoop dat jij een idee hebt.Mvg,
Roos
Reageren
Door
Luuk Tubbing
op
07 May 2017
Hoi Roos,
Daar kan ik je helaas niet mee verder helpen. SPSS is een veelgebruikte tool, dus ik denk dat Google je wel verder kan helpen. Succes!
Mvg,
Luuk
Reageren
Door
Renske
op
22 Feb 2017
Beste Luuk,Ik ben aan mijn scriptie aan het schrijven en loop vast op een bepaalde variabele. Van 12 verschillende items wil ik een somscore maken. Alle 12 de items worden gescoord op een Likert-schaal van 1 tot 6. Nu is het zo dat in mijn data-set sommige scores niet goed zijn ingevoerd. Zo staan er scores met allerlei decimalen tussen (bijv 1.38 of 4.45). Deze wil ik dus niet meenemen als ik de somscore ga maken.Ik wil deze afwijkende scores omzetten in missings, zodat ik die gemakkelijk kan excluderen bij het maken van de somscores en andere analyses. Ten eerste, is dit handig? En ten tweede, hoe kan ik dit doen?
Reageren
Door
Luuk Tubbing
op
23 Feb 2017
Beste Renske,
Als het niet al te veel verschillende getallen zijn kun je deze handmatig coderen als missing variable, zoals in bovenstaande artikel beschreven. Ik ben zelf niet bekend met een methode in SPSS om regels (bijv. 'maak van alle getallen met decimaal een missing variable') voor exclusie of missing variables toe te passen. Daar gebruik ik zelf Excel of SQL voor. Succes Renske!
Groeten,
Luuk
Reageren
Door
Esther
op
20 Feb 2017
Ik doe een studie naar migraine en wittestofafwijkingen. Ik heb bij zowel de controlegroep als de migrainegroep gekeken naar het wel of niet aanwezig zijn van cardiovasculaire risicofactoren, echter heb ik vrij veel missing values. Is het dan handig om het percentage en het aantal mensen van bijvoorbeeld het wel hebben van diabetes in de groep met bekende data aan te geven en dan in de discussie te spreken over dat er vrij veel missing values waren?Alvast bedankt voor uw reactie.
Reageren
Door
Luuk Tubbing
op
20 Feb 2017
Hoi Esther, de aantallen/percentages in het resultatenhoofdstuk, nog zonder duiding. Bespreking van de invloed van non-respons/missing values op de resultaten in het discussiehoofdstuk. Helder?
Groeten,
Luuk
Reageren
Door
richard
op
28 Jan 2017
Hoi Luuk,504 respondenten hebben de eerste 4 vragen beantwoord (demografische gegevens). Vervolgens hebben 466 respondenten (missing 38) de vragen over hun motivatie ingevuld. Daarna hebben 435 (69) respondenten de rest van de vragen ingevuld. Het aantal dat de totale vragenlijst heeft ingevuld is dus 435.Welke aantallen pak je nu wanneer je de respons (demografische gegevens) beschrijft? Pak je dan die 504 respondenten of de 435 respondenten die de totale vragenlijst hebben ingevuld?Ik ben benieuwd!Groeten,
Richard
Reageren
Door
Luuk Tubbing
op
28 Jan 2017
Hoi Richard,
Goede vraag! Het is zeker relevant om ook de demografische gegevens van de 'afvallers' te analyseren, zodat je evt verschillen met de respondenten kunt ontdekken. Als respons neem je het aantal respondenten dat de door jou beoogde vragen heeft ingevuld. Als het complex wordt kun je ook een tabelletje maken waarin je gefaseerd het aantal respondenten weergeeft, zodat direct helder is waar de 'afvallers' zitten. Helder? Succes met je verdere analyse!
Groeten,
Luuk
Reageren
Door
Richard
op
28 Jan 2017
Hoi Luuk,
Bedankt voor je snelle antwoord. Hier kan ik zeker wat mee.
Groetjes,
Richard
Reageren
Door
Elvir
op
17 Jan 2017
Hoi Luuk,
Ik vermoed dat ik iets niet heb vermeld of verkeerd heb verwoord. Enkel de ontevreden gasten kunnen reden aangeven waarom ze ontevreden zijn over het schoonmaakaspect. Dit zijn respondenten die het schoonmaakaspect met tussen 1-6 hebben beoordeeld (beoordelingscijfer). Dit houdt in dat iemand die een 7 heeft geggeevn, geen vervolgvraag krijgt. Ik vermoed echter dat diegene toch een bepaalde mening en of knelpunt ondervindt. (mijn onderzoek gaat over knelpunten in kaart brengen). Mijn vraag is of dit representatief is en of ik dit moet onderbouwen in de discussie hoofdstuk of conclusie hoofdstuk?Groet,
Reageren
Door
Luuk Tubbing
op
17 Jan 2017
Hoi Elvir,
Dat is dan een beperking van de verzamelde data. Inderdaad goed om te bespreken in het discussiehoofdstuk van je scriptie. Het blijft speculeren of de groep die een 7 of hoger heeft gegeven klachten hebben ondervonden over de schoonmaak en wat het verschil is met de '1-6 groep'. Daar kun je in het discussiehoofdstuk ook op ingaan als je daar goede onderbouwing voor hebt. Is dit een antwoord op jouw vraag?
Groeten,
Luuk
Reageren
Door
Elvir
op
16 Jan 2017
Hoi Luuk,Voor mijn onderzoek analyseer ik het doorlopende klanttevredenheidsonderzoek. Dit onderzoek richt zich op de gasten van de organisatie. Over een periode van 4 maanden hebben de gasten online 2600 enquêtes ingevuld. Mijn onderzoek richt zich op het schoonmaak aspect. Van deze 2600 ingevulde enquêtes geeft geeft 720 respondenten aan dat ze ontevreden zijn over schoonmaak. Echter kunnen ook de tevreden gasten een reden geven waaraan schoonmaak tekort schiet bij de organisatie te denken valt aan vieze vloeren.Mijn vraag is hoe ik dit moet interpreteren?
Reageren
Door
Luuk Tubbing
op
17 Jan 2017
Hoi Elvir, bedankt voor je vraag. Hoe je dat moet interpreteren hangt ervan af wat jouw onderzoeksvraag is. Als je (ook) geïnteresseerd bent in de relatie tussen algehele tevredenheid en tevredenheid over het schoonmaakaspect, dan is dit relevante informatie. Als je alleen in het schoonmaakaspect geïnteresseerd bent dan kun je de rest negeren. Is dit een antwoord op jouw vraag?
Groeten,
Luuk
Reageren
Door
Marèl
op
21 Dec 2016
Hoi Luuk,In onze opdracht moeten wij een logistic regression uitvoeren. Hierbij moeten wij de missing values buiten beschouwing houden. Waar moet je dit aangeven in SPSS?Groeten,
Marèl
Reageren
Door
Luuk Tubbing
op
22 Dec 2016
Beste Marel, zoals hierboven beschreven: een aparte code toekennen aan de missing values. Of bedoel je dat niet met buiten beschouwing laten?
Reageren
Door
Maartje
op
05 Dec 2016
Hallo! Voor mijn onderzoek moeten kinderen een vragenlijst invullen over uitstelgedrag, alleen zijn er bij veel respondenten missing values, doordat vragen niet zijn ingevuld. Kan ik dan beter de respondenten eruit halen of alleen de ingevulde waardes meenemen? Of ligt dat aan het aantal missings?Groetjes,
Maartje
Reageren
Door
Luuk Tubbing
op
05 Dec 2016
Hallo Maartje, bedankt voor je vraag. Dat hangt inderdaad af van het aantal missing values, maar ook van de mogelijke reden van niet invullen en de homogeniteit van de groep. Het kan zijn dat degenen die vragen hebben overgeslagen bijv. typische 'uitstellers' zijn, waardoor je een vertekent beeld krijgt.
Groetjes,
Luuk
Reageren
Door
Madelon
op
02 Dec 2016
Ik heb vraag 8 en vraag 8a. En vraag 8a hoef je alleen in te vullen als je vraag 8 met ''ja'' hebt beantwoord. Vraag 8a wordt dus soms niet ingevuld, omdat een persoon bij vraag 8 ''nee'' heeft ingevuld, maar moet ik dan alle niet ingevulde vragen van 8a met -99 invoeren. Of moet ik het anders in SPSS zetten?
Reageren
Door
Luuk Tubbing
op
02 Dec 2016
Dag Madelon,
Als het een groep blijft wel, maar als je met deze vraag een tweedeling wilt maken, dan krijg je twee verschillende datasets en is er geen sprake van missing values.
Groeten,
Luuk
Reageren
Door
Stijn
op
21 Nov 2016
Hallo,Ik ben bezig met een enquête. Mijn vraag is hoe ik de data verwerk van respondenten die een vraag hebben overgeslagen. In mijn enquête komt er namelijk bij een vraag (5) voor dat je bij "nee" naar vraag 7 moet gaan en dus vraag 6 overslaat. Bij deze respondenten staat er bij 6 dus niets. Hoe kan ik dit het beste verwerken?
Ik hoop dat mijn vraag een beetje duidelijk is.Alvast bedankt,Stijn
Reageren
Door
Luuk Tubbing
op
22 Nov 2016
Hallo Stijn,
Goede vraag. In feite zijn er geen missing values, want het gaat om twee verschillende groepen (groep "ja" en groep "nee") en dus twee verschillende (sub)datasets.
Groeten,
Luuk
Reageren
Door
Rachana
op
30 Jul 2016
Hoi Luuk,In mijn onderzoek hebben enkele respondenten mijns inziens teveel vragen niet ingevuld. Ik wil enkel de patienten die minder dan 4 missende waarden hebben meenemen in de analyse. Is er een manier om dit te ontwerpen in SPSS?Alvast bedankt voor je hulp!Groetjes Rachana
Reageren
Door
Rachana
op
30 Jul 2016
Nog een aanvulling: ik wil deze patienten (nog) niet uit mijn dataset gooien. Zat zelf te denken om dit te doen d.m.v. 'select cases', maar dat betekent dat je een nieuwe variabele zou moeten aanmaken met 1=4 missing. Ik weet echter niet of dit kan en hoe ik dat moet doen.Ik hoop dat mijn vraag zo duidelijk is!
Hoihoi!Ik heb een vraagje, ik heb 403 respondenten die mijn enquete hebben ingevuld en niet iedereen heeft alle vragen ingevuld. Hoe zit dat met het beschrijven van de resultaten? Moet je dan bij elke vraag zeggen hoeveel mensen de vraag hebben ingevuld en hoeveel procent daarvan een bepaald antwoord heeft gegegeven? Of kun je gewoon zeggen, van de 403 respondenten zegt .... % van hen het volgende:... Of moet je dan zeggen van : op deze vraag hebben 396 respondenten gereageerd, hieruit blijkt dat ...% van hen het volgende vindt:..... Dankjewel alvast voor je hulp!!:D
Reageren
Door
Luuk Tubbing
op
29 Jul 2016
Hoi, het belangrijkste is dat je transparant bent over de response, mogelijke oorzaken van non-response en de gevolgen hiervan voor de validiteit van je conclusies (laatste twee punten bespreek je in de discussie). De volgorde is minder belangrijk. Kom je hier verder mee?
Hoi! Ik heb een vraag en ik hoop dat je me kunt helpen. Ik heb van 510 participanten de mate van angst gemeten (baseline) en na 2 jaar weer (follow-up). Nu zijn er in de tussentijd 109 participanten uitgevallen en nu moet ik kijken of deze groep selectief is, ik denk door middel van een Independent samples t-test. Van de follow-up heb ik vd uitvallers natuurlijk geen data, dus ik neem aan dat ik de data van de baseline hiervoor moet gebruiken en die 109 participanten af moet zetten tegen de overige 401 participanten(?). Maar, bij de t-test moet je dus een grouping variable invullen maar ik weet niet hoe ik deze groep moet maken zodat ik de test uit kan voeren. Heb jij hier een idee over? Alvast bedankt voor het meedenken!
Reageren
Door
Milou
op
12 Jul 2016
Beste Luuk,Een korte vraag over missing data: ik heb in mijn thesis bij ongeveer 0% van alle respondenten missing data. Alle missing data is veroorzaakt omdat respondenten halverwege de lijst gestopt zijn met invullen (mijn enquête was behoorlijk lang). Moet ik hun antwoorden meenemen of hun antwoorden weggooien? Of misschien iets anders?Nb. De data die mist zijn de onafhankelijke variabelen.Alvast bedankt!
Reageren
Door
Milou
op
12 Jul 2016
Ik bedoelde 9% haha
Reageren
Door
Luuk Tubbing
op
12 Jul 2016
Beste Milou,Dat hangt deels af van de vraagstelling van jouw onderzoek, maar in principe is het niet wenselijk om half ingevulde enquêtes in je analyse mee te nemen, zeker wanneer dat betekent dat je bepaalde relaties (tussen afhankelijke en onafhankelijke variabelen) niet meer kunt leggen voor een deel van de respondenten. Een interessante vraag is altijd: hebben de afgehaakte respondenten andere eigenschappen dan de respondenten die de enquête hebben afgerond.Anyway, welke keuze je ook maakt, je zult dit goed moeten onderbouwen in je scriptie en helder moeten zijn over de afwegingen en beperkingen.Kom je hier verder mee?Groeten,Luuk
Reageren
Door
Dimri
op
07 Jul 2016
Beste Luuk,Het verhaal over de missing values is voor mij duidelijk na het lezen van bovenstaand artikel. Voor mij is het wel onduidelijk over welke value ik moet geven aan het cijfer 0. Ik heb als voorbeeld een vraag: Wat is/zijn de voornaamste reden(en) voor het gebruik van een hartslagmeter. Deze vraag bestaat uit meerkeuze antwoorden. Als een respondent heeft gekozen voor: Het meten van het omslagpunt, staat deze met 1 aangegeven. Dit is duidelijk dat ik deze de naam moet geven van het meten van het omslagpunt. Als de respondent niet voor dit antwoordt heeft gekozen staat er een: 0. Moet ik deze 0 benoemen bij value? Of is dit niet nodig?
Reageren
Door
Luuk Tubbing
op
07 Jul 2016
Beste Dimri,
Als ik het goed begrijp heb je dus ja/nee-vragen of checklistvragen? Dan zeg ik: ja = 1, nee = 0. De specifieke duiding van de getallen (buiten missing values) is vaak niet van wezenlijk belang om de analyse goed uit te kunnen voeren, maar wel voor de presentatie van de resultaten. Begrijpen we elkaar? Groeten, Luuk
Reageren
Door
Dimri
op
07 Jul 2016
Ik bedoelde meer dat ik een meerkeuze vraag heb. In één kolom staat dan 1 keuze antwoordt: bijvoorbeeld het meten van het omslagpunt staat dan als 1 als iemand deze heeft geselecteerd. Als iemand een andere meerkeuze antwoordt heeft geselecteerd staat in een ander kolom bij bijvoorbeeld looptechniek een 1. Als de respondent het omslagpunt niet meet staat in die kolom een 0 maar de respondent wel de looptechniek analyseren dan staat er in een nieuwe kolom een 1. Beetje lastig uit te leggen maar hoop dat het duidelijk is. Moeten deze 0 dus ook benoemd worden? Want dit is eigenlijk wat een respondent niet heeft aangevinkt bij de meerkeuzevraag in de enquete
Reageren
Door
Luuk Tubbing
op
07 Jul 2016
Ok, het zijn dus meerkeuzevragen, maar de antwoorden zijn wel binair (ja/nee) gecodeerd? Idealiter (maar ik weet niet welke analyses je gaat doen) heeft elke keuze een eigen nummer (1= omslagpunt, 2= looptechniek, etc.), omdat de vragen afhankelijk zijn van elkaar (je kunt maar één antwoord kiezen). Dan heb je maar één kolom per vraag met één getal per rij, i.p.v. per vraag een rij met een verzameling van enen en nullen. Hoe dan ook is het handig om alle keuzemogelijkheden te coderen. Is dat een antwoord op jouw vraag?
Reageren
Door
Marlous
op
21 Jun 2016
Hoi Luuk,
Ook ik ben momenteel bezig met mijn masterscriptie. Ik heb mijn missing values gecodeerd als '99'. Nu heb ik van de verschillende items (47 items), 5 variabelen gemaakt door middel van een meanscore. Echter, als ik kijk naar de meanscore per respondent berekent spss ook een meansscore voor de gene die een missing value hebben. Bijvoorbeeld een variabele bestaat uit 10 items en een respondent mist 2 items, dan berekent spss wel een meansore voor deze respondent over de 8 overige items.
Ik ga een logistische regressie uitvoeren. Neemt spss dan de meanscores mee van de respondenten die missingvalues hebben? En dus een meanscore hebben met minder items? Het is toch de bedoeling dat spss deze respondenten niet meeneemt in de analyze?
Want bij een logistische regressie kan je niet kiezen voor pair/listwise verwijderen?
Ik hoop dat je mij kunt helpen :)Dankjewel,
Groeten Marlous
Reageren
Door
Luuk Tubbing
op
21 Jun 2016
Hoi Marlous,
Bedankt voor je vraag. Bij logistische regressie worden alle cases met missing values als listwise behandeld, hetgeen
betekent dat ze niet worden meegenomen in de analyse. Het is niet mogelijk om een pairwise analyse te doen (wel in de syntax editor met het commando '/MISSING=INCLUDE'). Helder?
Groeten,
Luuk
Reageren
Door
Marlous
op
21 Jun 2016
Hoi Luuk,
Bedankt voor je snelle antwoord. Klopt het dat spss wél een meanscore berekent voor de respondenten met missing values? Maar deze uiteindelijke score wordt dus NIET meegenomen in de logistische regressie?
Groeten Marlous
Reageren
Door
Luuk Tubbing
op
21 Jun 2016
Hoi Marlous, antwoord op jouw tweede vraag is ja. Antwoord op jouw eerste vraag: ik weet niet precies waar je op doelt en waarom deze vraag relevant is, misschien omdat het lang geleden is dat ik voor het laatst logistische regressie heb gedaan. Gr, Luuk
Reageren
Door
Danya
op
16 Jun 2016
Hallo Luuk,
Ik ben momenteel bezig met data in spss waarbij er geen missing values zijn maar ik toch in de output van een frequentieverdeling missing system zie staan. Ik heb de reacties in surveymonkey nogmaals gecheckt maar daar staan geen missings in (had voor versturen enquete ook de optie dat het niet mogelijk is een antwoord over te slaan aangevinkt) Hoe kan het dat dit nu wel in mijn spss output staat? Moet ik dit negeren en alleen kijken naar percent ipv valid percent?Groeten,
Danya
Reageren
Door
Luuk Tubbing
op
17 Jun 2016
Hallo Danya, dat kan ik op afstand niet beoordelen aangezien ik niet weet welke handelingen je hebt uitgevoerd en hoe jouw dataset eruit ziet. Groeten, Luuk
Reageren
Door
Emma
op
31 May 2016
Hoi Luuk, ik ben bezig met een onderzoek en daarbij heb ik 1 vragenlijst gebruikt voor twee verschillende groepen. Ik ben begonnen met een aantal algemene vragen en daarna is vraag gesteld of de respondent "A" of "B" is. Daarna werd deze naar de goede vragenlijst doorgestuurd. Hierdoor heb ik dus een gedeelte dat voor iedereen is ingevuld (het begin) en daarna een gedeelte alleen door A/B. Hoe moet ik hier omgaan met de missing values? De aparte vragenlijsten zijn overigens wel gespiegeld voor A/B. Dezelfde vragen werden gesteld alleen bekijkt A het uit een ander perspectief dan B. De lengte voor de individuele vragenlijst is dus ook even lang.
Reageren
Door
Luuk Tubbing
op
31 May 2016
Hoi Emma, dat hangt er helemaal vanaf welke analyses je gaat doen. Als je de twee groepen statistisch met elkaar gaat vergelijken is het handig om dezelfde vragen van beiden groepen naast elkaar te hebben (onder dezelfde variabele/kolom). In dat geval raad ik je aan om eerst in Excel dezelfde vragen/variabelen van beide groepen naast elkaar te zetten voordat je deze in SPSS importeert. Als je de twee groepen apart gaat analyseren zou ik twee aparte datasets maken. Dan heb je sowieso geen missing values, want dan kun je de niet-ingevulde vragen (kolommen) helemaal weglaten. Het coderen van missing values is dus te vermijden. Is dit een antwoord op jouw vraag?
Reageren
Door
Emma
op
02 Jun 2016
Hoi Luuk, bedankt voor je reactie ik kan hier zeker wat mee! Alleen is mijn vraag nu; hoe moet ik deze dan coderen? Hoe splits ik de ene groep van de andere groep? Deze twee groepen staan namelijk helemaal door elkaar. Het is dus niet zo dat 1 t/m 50 groep A is en 51 t/m100 groep B. Hoe zou ik deze twee van elkaar kunnen splitsen dat ik twee datasets heb?
Of hoe zou ik het via excel aan kunnen pakken?
Reageren
Door
Luuk Tubbing
op
02 Jun 2016
Hoi Emma, graag gedaan. In Excel kun je met de filter een van de kolommen sorteren die de twee groepen onderscheidt. Dus één van de vragen die de ene groep wel en de andere groep niet heeft ingevuld, zodat de lege cellen boven- of onderaan komen en daarmee de groepen worden gescheiden. Is het idee helder? Als je technisch niet weet hoe Excel werkt is het handiger om dit even te Googelen dan dat ik hier een heel Excel handboek ga schrijven ;)
Reageren
Door
Ema
op
02 Jun 2016
Hoi Luuk, bedankt voor deze tip! Ik ga even uitzoeken in excel hoe ik het kan filteren. Bedankt voor de hulp!
Reageren
Door
Dané
op
25 May 2016
Beste Luuk,
Voor mijn scriptie doe ik onderzoek naar het eetgedrag van adolescenten in een klas en de invloed van het eetgedrag van populaire leeftijdgenoten daarop. Om te bepalen wat voor eetgedrag adolescenten hebben zijn er meerdere food frequency vragen afgenomen (hoe vaak je in een week fruit / groente / snoep etc.) deze vraag is op een 7 punts Likert schaal beantwoord die loopt van 1 (nooit) t/m 7 (iedere dag meerdere keren). Nu zijn er een aantal respondenten die deze vraag niet hebben ingevuld en dus geen waarde hebben in SPSS. Moet in deze respondenten als missing behalen? En als dat zo is hoe moet ik dat doen, want deze mensen hebben geen waarden?
Reageren
Door
Luuk Tubbing
op
25 May 2016
Beste Dané, als het wel de bedoeling was dat deze vraag werd ingevuld dan zijn dat inderdaad missing values (tip voor de volgende keer: maak vragen verplicht), maar je hoeft niet telkens de hele respondent weg te gooien. Een stappenplan:
- Je vult eerst de lege velden in met een getal. Dat gaat als volgt: ga naar Transform – Recode into Same Variables; alle variabelen naar rechts; vink System or User-Missing aan; voer rechts een waarde in (bijv. 0 of 99) en voeg deze toe.
- Codeer de missing values naar het gekozen getal (zoals in t artikel beschreven, met discrete missing values)
- Bij de analyses kies je voor exclude cases pairwise.
Kom je verder met dit antwoord? Succes! Groetjes, Luuk
Reageren
Door
Laura
op
13 May 2016
Hoi!
Ik doe voor mijn sctiptie een patienttevredenheidsonderzoek in een ziekenhuis door middel van een vragenlijst met gesloten vragen, nu hebben patienten sommige vragen niet ingevuld.
Als ik wat u heeft uitgelegd ga toepassen in SPSS worden dan alleen de lege hokjes(niet ingevulde antwoorden) niet meegenomen bij de analyses of worden dan alle antwoorden die de persoon heeft gegeven bij de vragenlijst niet meegenomen?
Een andere site heeft het namelijk over Listwise deletion of missing values en Pairwise deletion of missing values.
Het is namelijk de bedoeling dat alleen de lege hokjes niet moeten worden meegenomen in de analyses maar wel de rest van de antwoorden die de patient heeft gegeven.Met vriendelijke groet,
Laura
Reageren
Door
Luuk Tubbing
op
15 May 2016
Hoi Laura, bedankt voor jouw vraag. Bovenstaande artikel gaat over het coderen van missing values. Het pairwise dan wel listwise excluderen van missing values kun je aangeven in het optiemenu bij de betreffende analyse> Dat ziet er ongeveer zo uit: http://phantichspss.com/wp-content/uploads/2015/09/list11.jpg
In jouw geval is pairwise van toepassing. Groet, Luuk
Reageren
Door
Brecht
op
08 May 2016
Beste Luuk,
Voor mijn masterproef doe ik onderzoek naar genderverschillen en jobtevredenheid bij bedienden tussen de 30 en 45 jaar. Mijn eerste twee vragen in mijn enquete waren "bevindt u zich tussen de 30 en 45 jaar?" en "Bent u bedende?". Wanneer de respondenten "nee" antwoorden, worden ze direct naar het einde van de enquete gestuurd.
Nu ben ik bezig aan de analyse van mijn data. De "nee" antwoorden op de vragen zijn dus missing values. Maar hoe moet ik hiermee omgaan? Want als ik bij discrete missing value '2' ingeef, veranderd er niet aan mijn data view en staan deze er nog steeds tussen.
Of kan ik deze zelf verwijderen uit de data view? Want van deze respondenten is er geen data omdat ze niet voldeden aan de criteria, dus zijn verwaarloosbaar.
Alvast bedankt!
Reageren
Door
Luuk Tubbing
op
09 May 2016
Beste Brecht, bedankt voor je vraag. De "nee" antwoorden zijn geen missing values (valt buiten de onderzoekspopulatie) en kun je inderdaad zelf verwijderen. Succes!
Reageren
Door
Suzanne
op
03 May 2016
Beste Luuk,
Ik heb bij variable view de missings nu gedefinieerd als 99, echter staan ze in data view nog gewoon als lege cel. Neemt SPSS deze missings automatisch goed mee?
Reageren
Door
Luuk Tubbing
op
03 May 2016
Beste Suzanne, op afstand durf ik niet te zeggen waar dat aan ligt. Als je bovenstaande procedure volgt gaat dat verder automatisch ja.
Reageren
Door
Sanne
op
03 May 2016
Hoi, ik heb een vraag. Ik wil graag een missing value toevoegen (namelijk 0, dit staat voor n.v.t.) voor alle vragen in mijn vragenlijst. Moet dit per vraag gedaan worden of is er ook een snellere manier? Anders ben ik echt heel lang bezig.
Groetjes, Sanne
Reageren
Door
Luuk Tubbing
op
03 May 2016
Dat durf ik niet te zeggen, want ik weet niet hoe jouw dataset eruit ziet. Bedoel je dat je per vraag een kolom gaat toevoegen met n.v.t.? Zo ja, dan kun je de velden in deze kolom leeg laten en een vaste waarde geven door ze als missing value te definiëren.
Reageren
Door
Sophie
op
22 Apr 2016
Thanks voor de top uitleg. Ik heb al mijn missing aangepast in mijn data en dat ging goed. Maar ik heb nu in totaal 161 respondenten en bij een bepaalde vraag mis ik 2 antwoorden, dus 2 respondenten. Nu wil ik een tabel maken zodat n=159 100%, maar dit krijg ik niet voor elkaar. Ik krijg gewoon n=159 en dat is bijv. bij elkaar 98%. Hoe zorg ik er voor dat de missing niet wordt meegerekend en dat n=159 100% wordt?
Reageren
Door
Luuk Tubbing
op
03 May 2016
Hoi Sophie, jouw reactie had ik over het hoofd gezien. Is jouw probleem nog actueel?
Reageren
Door
Iris
op
22 Apr 2016
Beste Luuk,
Voor mijn masterscriptie doe ik onderzoek naar de taalontwikkeling van jonge kinderen. Deze is op drie leeftijden gemeten, wat zorgt voor longitudinale data. Nou is er van een aantal participanten data van alle drie de meetmomenten, maar sommigen hebben alleen nog maar meegedaan aan het eerste meetmoment (omdat ze nog niet oud genoeg zijn voor de volgende meetmomenten). Van hen is er dus nog geen data op het 2e en 3e moment, maar die komt in de toekomst wel (niet meer tijdens mijn scriptie).
Moet ik deze data die nog niet verzameld is, wel allemaal markeren als missings (999)? Of kan ik deze cellen dan gewoon leeg laten?
Alvast bedankt!
Reageren
Door
Luuk Tubbing
op
22 Apr 2016
Beste Iris, je kunt als inclusiecriterium stellen dat er per kind drie meetmomenten beschikbaar moeten zijn. Dan zijn de ontbrekende waarden geen missing values meer (de meting moet immers nog plaatsvinden), maar data die buiten de scope van jouw onderzoek valt. De incomplete regels kun je dan uit je dataset verwijderen. Wel zul je helder moeten hebben of je dan niet het risico loopt om echte missing values (bijv. kinderen die niet kwamen opdagen voor een meting) verwijderd, als die niet apart zijn gecodeerd. Als dit risico bestaat, dan wel in je scriptie vermelden, bijv. in het discussiehoofdstuk. Helpt dit antwoord jou verder?
Groet, Luuk
Reageren
Door
Rowan
op
07 Apr 2016
Hoi Luuk,Ik doe onderzoek naar factoren die de koopintentie van consumenten en prospects beïnvloeden op dag-deal websites zoals Social Deal. In mijn online enquête heb ik onderscheid gemaakt tussen consumenten en prospects, waardoor consumenten andere vragen te zien krijgen als prospects, en andersom. Met andere woorden; deze vragen zijn dus logisch 'gerout' en het gaat totaal over 5 vragen die gerout zijn. De overige vragen over de factoren zijn wel hetzelfde voor consumenten en prospects.
Nu heb ik in SPSS in 'Variable View' bij de geroute vragen dus soms lege vakjes. Is het voldoende om in Variable View bij die lege vakjes overal een 99 invullen, zodat SPSS 'snapt' dat bij die vragen - afhankelijk of je consument of prospect bent - soms niks in hoeft te worden gevuld?Alvast bedankt!
Reageren
Door
Rowan
op
07 Apr 2016
Sorry, in dit onderstaande stuk bedoelde ik met Variable view Data view!Nu heb ik in SPSS in 'Variable View' bij de geroute vragen dus soms lege vakjes. Is het voldoende om in Variable View bij die lege vakjes overal een 99 invullen, zodat SPSS 'snapt' dat bij die vragen - afhankelijk of je consument of prospect bent - soms niks in hoeft te worden gevuld?
Reageren
Door
Luuk Tubbing
op
08 Apr 2016
Hoi Rowan, bedankt voor je vraag. Interessant onderzoek trouwens :) Zoals in bovenstaande artikel beschreven, kun je in de Variable View aangeven welke waarde/codering een missing value (een lege cel in de Data View) krijgt, zodat je dit niet handmatig hoeft in te voeren. Je kiest dan voor de optie Discrete missing values en voert het gewenste getal in (zie bovenstaande instructie). Is dat een antwoord op jouw vraag? Groetjes, Luuk
Reageren
Door
Gill
op
02 Apr 2016
Beste, Ik doe een onderzoek die peilt naar het zoekgedrag van werklozen over een periode van 5 weken. Elke week moeten de respondenten dezelfde weekvragenlijst invullen over de organisatie waar ze de laatste week gesolliciteerd hebben. Het spreekt voor zich dat sommige respondenten niet zullen solliciteren in die week en dus ook die vragen niet hoeven te beantwoorden. Al die cellen blijven dus leeg en dit verschijnt ook zo in SPSS. Hoe raadt u mij aan om hier mee rekening te houden aangezien mijn onderzoek uitgaan van een within subject design.
Reageren
Door
Luuk Tubbing
op
04 Apr 2016
Dat hangt van het onderzoeksdoel en of je non-respons gelijk kunt stellen aan niet solliciteren. Ik zie in ieder geval twee stappen: (1) wel/niet gesolliciteerd en (2) antwoord op vragen. De lege velden zou ik niet als missing values behandelen, omdat het (per week) om een andere deelpopulatie gaat (wél gesolliciteerd).
Reageren
Door
Tanya
op
28 Mar 2016
Hey. Dit hebben we al een paar keer geprobeerd, maar er veranderd niets bij data view en de cellen blijven leeg. Wat kan hier de oorzaak van zijn?
Reageren
Door
Luuk Tubbing
op
29 Mar 2016
Hey Tanya, dat durf ik niet te zeggen op afstand. Mvg, Luuk
Reageren
Door
Nini
op
24 Mar 2016
Hoi! Allereerst bedankt voor je heldere uitleg. Ik heb nog een vraag. Moet je missing values ook bij 'values' definiëren of moet dit alleen bij 'missing values' (zoals jij hierboven beschreven hebt)? Bijvoorbeeld:
1 = Zeer ontevreden
2 = Ontevreden
3 = Neutraal
4 = Tevreden
5 = Zeer tevreden
99 = Niet ingevuld (missing value)Alvast bedankt!
Groetjes Nini
Reageren
Door
Luuk Tubbing
op
24 Mar 2016
Hoi Nini, bedankt voor het compliment en jouw vraag. Je hoeft missing values niet bij values te definiëren. Het heeft geen invloed op de analyses (daarvoor geldt de procedure uit bovenstaande artikel), maar het kan natuurlijk wel handig zijn, bijvoorbeeld omdat je deze informatie wilt gebruiken bij het presenteren van resultaten.
Reageren
Door
E.B.
op
08 Dec 2020
Beste Luuk,Hoe zou jij omgaan met dubbele waardes? Als mensen twee antwoorden ingevuld hebben terwijl je aangegeven hebt dat het er maar 1 mocht zijn.
Dus ze hebben op een 5-puntschaal bijvoorbeeld 2 en 3 ingevuld?
Als missing of de laagste of hoogste kiezen overal?Alvast bedankt!
Reageren
Door
Silke
op
06 May 2021
Beste Luuk,Ik ben momenteel bezig met onderzoek naar student zijn vs niet student zijn. Nu hebben ongv 2000 participanten ingevuld wat hun werkzaamheden zijn (student, parttime werken, fulltime werken etc.). Ik wil nu een dummy variabele maken om een regressieanalyse te doen met 2 groepen: student en niet-student. Ik heb 1 item waar mensen antwoord hebben gegeven dat ze student zijn, en 8 items dat participanten antwoord hebben gegeven dat ze iets anders doen, aka geen student zijn. Nu heb ik de indruk dat ik alleen naar de kolom \'student zijn\' moet kijken om een dummy variabele te maken. Het enige probleem is dat er een aantal participanten zijn waar er een - in plaats van een 0 staat als ze geen student zijn. Is dit dan een missende waarde? Hoe kan ik ervoor zorgen dat ook deze (-) participanten worden meegenomen in de analyse als ik een dummy variabele maak?
Reageren
Door
Tina
op
31 May 2021
Beste Luuk,
Ik ben bezig met het analyseren van vragenlijst. We hebben 12 vragen bij 500 mensen afgenomen. Nu wil ik het gemiddelde van de 12 vragen berekenen. In principe tel je dan gewoon alle 12 vragen bij elkaar op en \12. Maar er zijn een aantal missings. Het schijnt mogelijk te zijn om een statistical mean te berekenen, gecorrigeerd voor de missings (dus waar een missing is \11) en daar het gemiddelde van genomen. Klopt dat? Hoe zou ik dat moeten doen?
Dankjewel!
Reageren
Door
Robin
op
18 Jun 2021
Hoi Luuk,Voor mijn scriptie ben ik bezig met een onderzoek, waarbij ik gegevens van gezinnen onderzoek dmv een regressie-analyse. Zojuist ben ik er achter gekomen dat ik op 1 van de controlevariabelen een aanzienlijk aantal missende waardes heb (15.9%). Nu vraag ik me af of jij misschien weet in hoeverre dit, voor een controlevariabele, een probleem is. Zou het voldoende zijn om dit in de discussie te melden? Of bestaat hier nog een handige oplossing voor? Groetjes Robin
Reageren
Door
Jada
op
15 Sep 2021
Hai Luuk, ik doe onderzoek naar het effect van een warming up. Hiervoor volgen deelneemsters 8 weken een gestandaardiseerde warming-up. Deze dienen ze 3xpw (2 trainingen en 1 wedstrijd) uit te voeren. Er zullen ongetwijfeld gemiste trainingen en/of wedstrijden zijn in die 8 weken. Hoe kan ik die missing data het beste verwerken?
Reageren
Door
Jada
op
15 Sep 2021
Mijn vraag is niet helemaal correct; de data die ik invoer zijn kniehoeken voor en na interventie. Hoe kom ik erachter of ik bij het missen van 1 vd 2 metingen een deelneemster moet uitsluiten van analyse of die ene waarde wel mee mag nemen?Mocht je er ervaring mee hebben, of iemand anders; de training moet 8 weken duren om een effect te kunnen meten. Idealiter zijn dit 3 trainingsmomenten per week. Wat als een deelneemster niet 8 weken lang 3 keer per week heeft deelgenomen?



Yoni
op 12 Jul 2020Luuk Tubbing
op 12 Jul 2020Yanne
op 10 Apr 2020Mariska
op 17 Mar 2020Luuk Tubbing
op 17 Mar 2020Feray
op 22 Jan 2020Luuk Tubbing
op 22 Jan 2020Ymkje
op 29 Jul 2019Luuk Tubbing
op 30 Jul 2019Emma
op 21 May 2019Luuk Tubbing
op 21 May 2019Katrien
op 15 May 2019Luuk Tubbing
op 17 May 2019Bettine
op 18 Apr 2019Floor
op 01 May 2019Bettine
op 18 Apr 2019Nadianne van den Ende
op 19 Mar 2019Luuk Tubbing
op 20 Mar 2019Lieke
op 14 Feb 2019Michel
op 27 Mar 2020Michel
op 25 Mar 2020Luuk Tubbing
op 25 Mar 2020Luuk Tubbing
op 14 Feb 2019Jildou
op 29 Jan 2019Luuk Tubbing
op 29 Jan 2019Jantien
op 02 Jan 2019Luuk Tubbing
op 13 Jan 2019Britt
op 17 Nov 2018Luuk Tubbing
op 17 Nov 2018Katrin
op 28 Jul 2018Luuk Tubbing
op 29 Jul 2018Jildou
op 22 Jul 2018Luuk Tubbing
op 22 Jul 2018Jildou
op 21 Jul 2018Luuk Tubbing
op 22 Jul 2018Jildou
op 21 Jul 2018Luuk Tubbing
op 21 Jul 2018HenkJan
op 11 Jul 2018Luuk Tubbing
op 11 Jul 2018Smithd0
op 15 Jun 2018John
op 23 May 2018Luuk Tubbing
op 25 May 2018Sara
op 12 May 2018Luuk Tubbing
op 13 May 2018Ella
op 16 Apr 2018Luuk Tubbing
op 16 Apr 2018Sara
op 13 Apr 2018Luuk Tubbing
op 16 Apr 2018Tessa
op 17 Mar 2018Luuk Tubbing
op 17 Mar 2018Rob
op 16 Jun 2017Luuk Tubbing
op 16 Jun 2017Judith
op 23 May 2017Luuk Tubbing
op 24 May 2017Eva
op 19 May 2017Luuk Tubbing
op 20 May 2017Eva
op 07 May 2017Luuk Tubbing
op 08 May 2017Eva
op 19 May 2017Roos
op 03 May 2017Luuk Tubbing
op 07 May 2017Renske
op 22 Feb 2017Luuk Tubbing
op 23 Feb 2017Esther
op 20 Feb 2017Luuk Tubbing
op 20 Feb 2017richard
op 28 Jan 2017Luuk Tubbing
op 28 Jan 2017Richard
op 28 Jan 2017Elvir
op 17 Jan 2017Luuk Tubbing
op 17 Jan 2017Elvir
op 16 Jan 2017Luuk Tubbing
op 17 Jan 2017Marèl
op 21 Dec 2016Luuk Tubbing
op 22 Dec 2016Maartje
op 05 Dec 2016Luuk Tubbing
op 05 Dec 2016Madelon
op 02 Dec 2016Luuk Tubbing
op 02 Dec 2016Stijn
op 21 Nov 2016Luuk Tubbing
op 22 Nov 2016Rachana
op 30 Jul 2016Rachana
op 30 Jul 2016Luuk Tubbing
op 01 Aug 2016MO
op 27 Jul 2016Luuk Tubbing
op 29 Jul 2016Luuk Tubbing
op 17 Jul 2016Jennifer
op 13 Jul 2016Milou
op 12 Jul 2016Milou
op 12 Jul 2016Luuk Tubbing
op 12 Jul 2016Dimri
op 07 Jul 2016Luuk Tubbing
op 07 Jul 2016Dimri
op 07 Jul 2016Luuk Tubbing
op 07 Jul 2016Marlous
op 21 Jun 2016Luuk Tubbing
op 21 Jun 2016Marlous
op 21 Jun 2016Luuk Tubbing
op 21 Jun 2016Danya
op 16 Jun 2016Luuk Tubbing
op 17 Jun 2016Emma
op 31 May 2016Luuk Tubbing
op 31 May 2016Emma
op 02 Jun 2016Luuk Tubbing
op 02 Jun 2016Ema
op 02 Jun 2016Dané
op 25 May 2016Luuk Tubbing
op 25 May 2016Laura
op 13 May 2016Luuk Tubbing
op 15 May 2016Brecht
op 08 May 2016Luuk Tubbing
op 09 May 2016Suzanne
op 03 May 2016Luuk Tubbing
op 03 May 2016Sanne
op 03 May 2016Luuk Tubbing
op 03 May 2016Sophie
op 22 Apr 2016Luuk Tubbing
op 03 May 2016Iris
op 22 Apr 2016Luuk Tubbing
op 22 Apr 2016Rowan
op 07 Apr 2016Rowan
op 07 Apr 2016Luuk Tubbing
op 08 Apr 2016Gill
op 02 Apr 2016Luuk Tubbing
op 04 Apr 2016Tanya
op 28 Mar 2016Luuk Tubbing
op 29 Mar 2016Nini
op 24 Mar 2016Luuk Tubbing
op 24 Mar 2016E.B.
op 08 Dec 2020Silke
op 06 May 2021Tina
op 31 May 2021Robin
op 18 Jun 2021Jada
op 15 Sep 2021Jada
op 15 Sep 2021