One-way ANOVA met SPSS
T-toets met SPSS


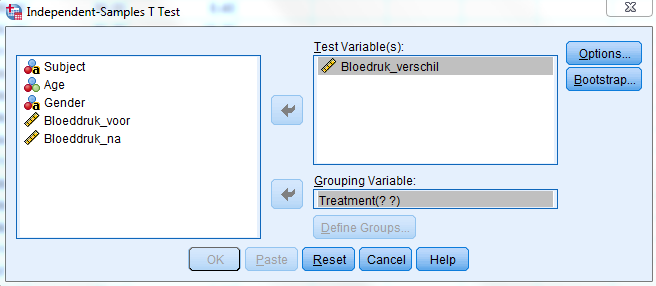
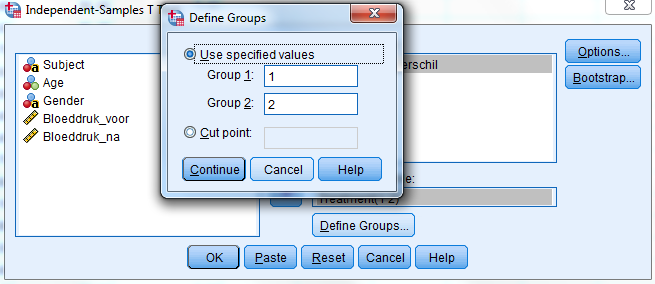
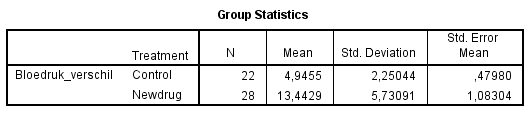

Gemiddeld hadden participanten die het nieuwe medicijn namen (gem. = 13,44; SD = 5,73) een grotere bloeddrukdaling dan participanten uit de controlegroep (gem. = 4,95; SD = 2,25). Dit verschil, p = 0,000, is significant.
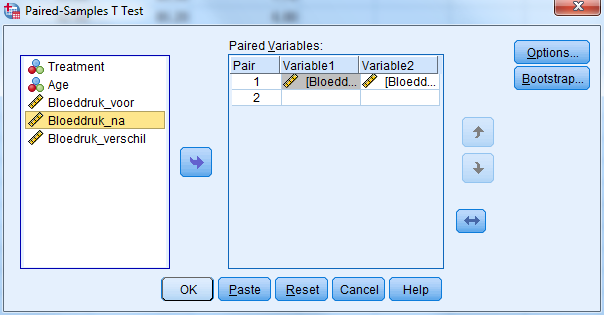
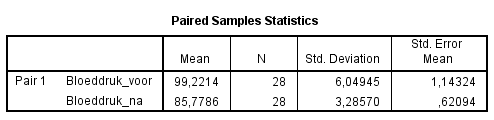
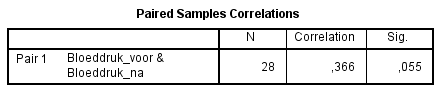

Gemiddeld hadden participanten voordat ze het medicijn namen (gem. = 99,22; SD = 6,05) een hogere bloeddruk dan nadat ze het medicijn namen (gem. = 85,78; SD = 3,29). Dit verschil, p = 0,000, is significant.
